Our current collection policy covers metadata records for geodata (open data and licensed databases) and historical scanned maps.
Collection A: DATA REGISTRY
1. Open Data Registry
Regularly updated registry of public geodata available from hundreds of public sites, including state and local governments, research institutes, and libraries.
Curation goals:
metadata normalization and enhancement
transformations into a schema specifically designed for
geospatial resources
searchable by text string, dates, place names, and with a map
interface
federated search of hundreds of sites at once.
2. Licensed Data Registry
Index of all layers within complex licensed databases that various BTAA Universities subscribe to.
Curation goals:
an index of all layers within the databases
provide normalized federated search of hundreds of sites and
databases at once.
Collection B: LIBRARY REPOSITORIES
Scanned maps and geodata held at BTAA university digital libraries.
Curation goals:
metadata improvements from regular cleanup sprints to fix
bounding box errors, creator normalization, date normalization,
and application of linked data URIs.
provide normalized federated search of all geospatial resources held at BTAA libraries in one site
augment search capabilities beyond typical library catalogs, including spatial and temporal searches
We rely on two open-source tools for our workflows: the BTAA Geoportal
and GeoBlacklight Admin, a custom administrative toolkit. Both tools
run on Amazon Web Services (AWS). Under our current scope, we are only
able to provide access as external links to the most recent versions
of any dataset. When authors overwrite a public dataset, we must
re-harvest the metadata and discard the previous version with its
broken access links.
1.2 Expanded Operations: Add Data Curation with Cloud Storage
Our planned collection policy would continue to cover metadata records
for open data, licensed data, and scanned maps. It would expand to
include a curated collection of public data, selectively chosen with
the BTAA researchers in mind. To develop this new aspect of the
collection policy, we will develop these four areas:
STAFFING: Shift the focus of our Product Manager to include the role
of Geospatial Data Curator and hire a Program and Outreach
Coordinator to manage the increased complexity of the BTAA-GIN.
CURATION: Collaboratively develop a curation plan that identifies
datasets based on criteria such as theme, geography, temporal
range, data quality, and administrative source.
QUALITY CONTROL: Determine our data and metadata quality standards,
such as the principles of FAIR (Findability, Accessibility,
Interoperability, and Reuseability).
COMMUNICATION: Create a data provider communication plan for
obtaining historical datasets and current datasets at regular or
as-needed intervals.
New Collection C: BTAA-GIN Geodata
Free and open geodata curated and stored by the BTAA-GIN. Curation goals:
capture snapshots of recently published at-risk resources that
will be overwritten
fill in the gaps of hidden or unpublished datasets from the early
digital era
save a historical record of the changing geospatial landscape
provide a consistent user experience that minimizes broken links
To incorporate data curation, we will expand the functionality of GBL
Admin to include data ingest and management. This will involve setting
up cloud object storage with Amazon S3 to store and provide access to
the curated resources. Under our expanded scope, users will still be
able to access current versions from the original data provider, but
will also be able to download historical versions.
Obtain official approval of the BTAA-GIN Geodata Collection
Strategic Plan.
Document the setup and configuration processes: Create detailed
documentation on the setup of S3 accounts and asset management
tools.
Define and document pilot testing procedures: Establish how the
testing of sample datasets will be conducted, including success
criteria and evaluation metrics.
2.2 Develop Curation Plan and Explore Technology Enhancements (2024 Q3-Q4)
Publish Geoportal design enhancements to the production site:
Transition the updated Geoportal interface from the development
branch to the live environment, ensuring all new features are
fully operational.
Conduct final testing of the enhanced Admin Toolkit: Ensure that the
new batch asset management functionalities are working as intended
and integrate feedback from the pilot phase.
Set up monitoring tools for the new systems: Implement tools to
continuously monitor the performance and usage of the Geoportal
and data repository, ensuring they meet user needs and technical
requirements.
Review initial active curation outcomes: Evaluate the effectiveness
of the curation process, identifying areas for improvement or
adjustment.
Develop and execute an outreach plan: Create a detailed plan for
engaging with the community, including conferences, webinars, and
workshops to showcase the project.
Prepare and publish outreach materials: Design and distribute
materials to highlight the project’s features and benefits.
Conduct program evaluation: Assess the project’s impact on users and
stakeholders, evaluating how well the curation plan and new
systems are meeting the established goals.
Gather and analyze user feedback: Use surveys, interviews, and usage
data to understand user experiences, satisfaction, and areas for
improvement.
Amazon Cloud Object Storage will serve as the primary storage solution,
selected for its efficiency, scalability, and cost-effectiveness. It
provides a flat storage structure that simplifies management.
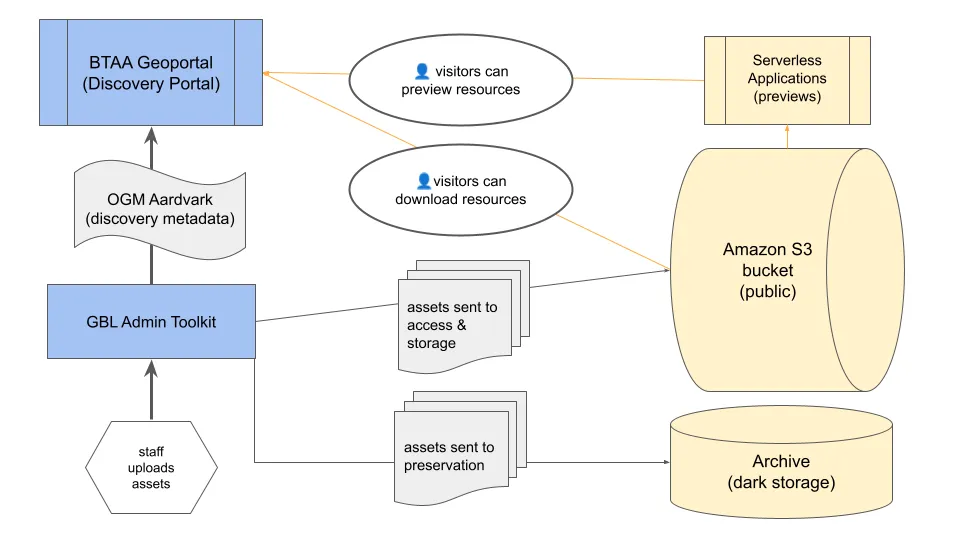
A curator manually creates a metadata record using the GBL Admin
Toolkit’s user interface, adhering to the OpenGeometadata
Aardvark schema.
Data Upload and Storage:
The curator uploads the zipped geospatial dataset, bundled with
a standards-compliant metadata file, through the GBL Admin
interface.
GBL Admin then pushes this dataset to an Amazon S3 bucket for
public access and to AWS Glacier for dark storage (future
implementation).
Data Preview and Metadata Access:
The S3 bucket integrates with serverless applications to offer
data previews to users.
The curator uploads a separate standards-based XML metadata file
via the GBL Admin UI, which is also stored in S3. This allows
users to preview the metadata independently before downloading
the dataset.
Curators will prepare a spreadsheet containing metadata in the
OpenGeoMetadata Aardvark schema.
They will then upload this spreadsheet to the GBL Admin Toolkit
to create multiple metadata records simultaneously.
Data Batch Upload
The method for batch uploading of datasets and associated XML
metadata files is yet to be defined. The future system will
likely allow curators to upload multiple datasets and their
metadata files to the GBL Admin Toolkit, which will then
automate the process of storing these in AWS S3 and handling
their integration with serverless applications for previews.